Office 下载、安装、激活,有它就够了!
为了下载 Office,我们往往最先想到的就是利用搜索引擎查找。但搜索结果往往五花八门、鱼龙混杂,很难找到一个安全、正规的网站可以下载 Office。下载好之后,Office 的安装过程也并不那么友好。还有许多人最关心的激活问题。
因此,接下来要介绍的是一款与 Office 有关的小工具——Office Tool Plus,简称 OTP。麻雀虽小,五脏俱全。OTP 能够对 Office 实现一站式管理、安装、激活、卸载等,支持 Office 365、Office 2019 和 Office 2016 等。此外,其还内置了一些十分实用的小工具。
下载 OTP 工具
首先,到 Office Tool Plus 网站下载 OTP。将其放到全英文路径中,然后打开运行。
主界面如下:

OTP 主界面
随着软件的持续更新,界面可能会有明显的变化,但核心操作的流程应当是一样的。
需要注意的是,如果电脑上已经安装了其他版本的 Office 和相关插件等,需要先卸载,卸载完毕后需要重启电脑。卸载可以在 OTP 中进行:
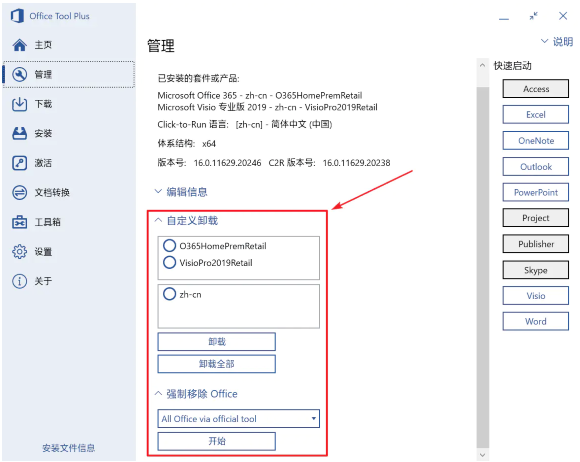
在 OTP 中卸载 Office
安装 Office
如果网速比较好的话,可以选择直接在线安装,否则选择离线安装。
在线安装
直接切换到「安装」选项卡,无需先行手动下载。
在安装时,需要根据将要安装的 Office 的不同版本,对「Office 套件」项进行选择:
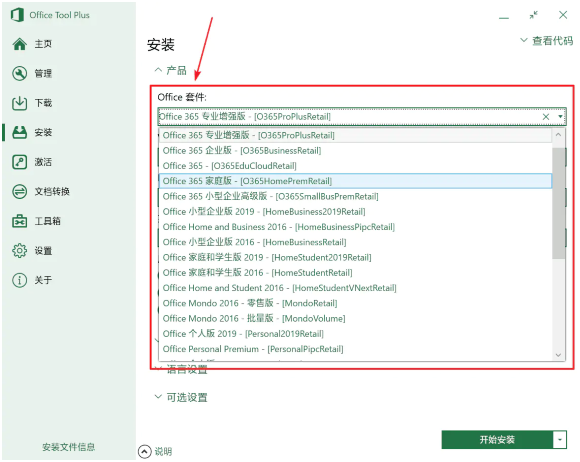
选择「Office 套件」
这里需要说明的是,由于 Visio 和 Project 是从 Office 中独立出来的,因此需要单独选择。
如下是一些常见的示例:
Office 版本 Office 套件 ID
| Office 2019 专业增强版(零售) | ProPlus2019Retail |
| Office 2019 专业增强版(批量) | ProPlus2019Volume |
| Office 2019 家庭和学生版 | HomeStudent2019Retail |
| Office 2016 专业增强版(零售) | ProPlusRetail |
| Office 2016 专业增强版(批量) | ProPlusVolume |
| Office 2016 家庭和学生版 | HomeStudentRetail |
| Office 365 个人版、家庭版 | O365HomePremRetail |
| Office 365 教育版、E3 等 | O365ProPlusRetail |
Visio 版本 Visio ID
| Visio 2019 专业版(零售) | VisioPro2019Retail |
| Visio 2019 专业版(批量) | VisioPro2019Volume |
| Visio 2016 专业版(零售) | VisioProRetail |
| Visio 2016 专业版(批量) | VisioProVolume |
| Visio 2019 标准版(零售) | VisioStd2019Retail |
| Visio 2019 标准版(批量) | VisioStd2019Volume |
| Visio 2016 标准版(零售) | VisioStdRetail |
| Visio 2016 标准版(批量) | VisioStdVolume |
Project 版本 Project ID
| Project 2019 专业版(零售) | ProjectPro2019Retail |
| Project 2019 专业版(批量) | ProjectPro2019Volume |
| Project 2016 专业版(零售) | ProjectProRetail |
| Project 2016 专业版(批量) | ProjectProVolume |
| Project 2019 标准版(零售) | ProjectStd2019Retail |
| Project 2019 标准版(批量) | ProjectStd2019Volume |
| Project 2016 标准版(零售) | ProjectStdRetail |
| Project 2016 标准版(批量) | ProjectStdVolume |
之后,根据自己的需要,在「应用程序」区选择将要安装的 Office 组件:
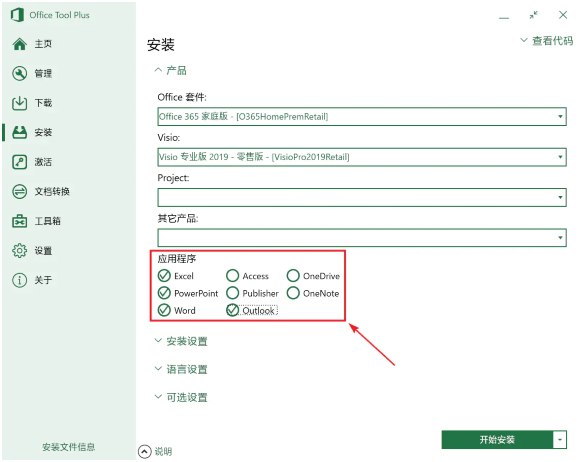
选择 Office 组件
「体系结构」部分,64 位(x64)Windows 可以安装 64 位和 32 位的 Office,32 位(x86)Windows 只能安装 32 位的 Office。至于如何选择,可以参考这篇文章。
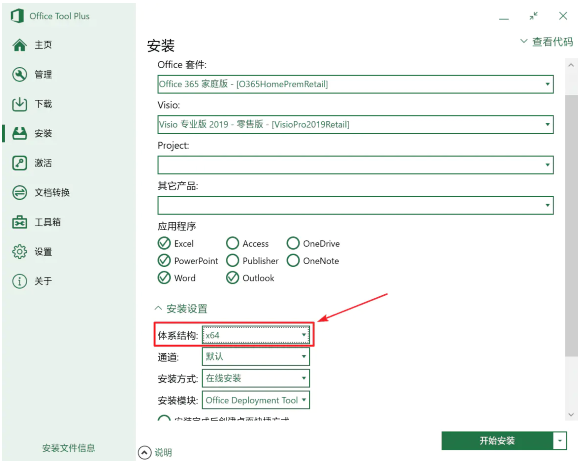
选择安装 64 位 Office
「通道」保持默认即可。有需要的可以自行修改。
在全部选择完成后,点击「开始安装」,便会开始安装过程:

Office 在线安装
离线安装
下载
切换到「下载」选项卡,先下载离线包,再安装。
「通道」保持默认的「每月通道」即可。有需要的可以自行修改。
「体系结构」部分,64 位(x64)Windows 可以安装 64 位和 32 位的 Office,32 位(x86)Windows 只能安装 32 位的 Office。至于如何选择,可以参考这篇文章。两者都下载的,选择「All」:
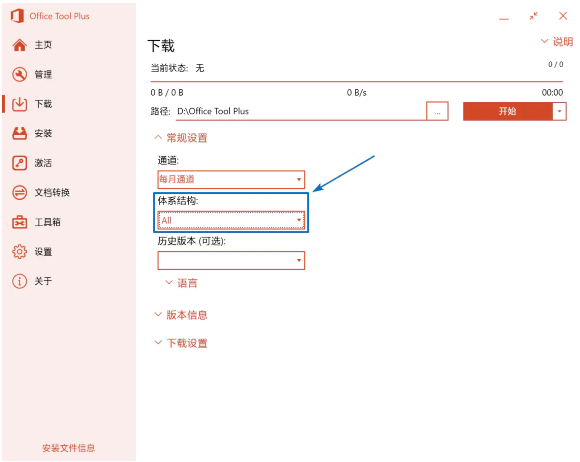
选择下载 32 位和 64 位的 Office
然后点击「开始」即可下载。下载完成后,OTP 会识别到已下载的离线包,显示其版本号、体系结构等:
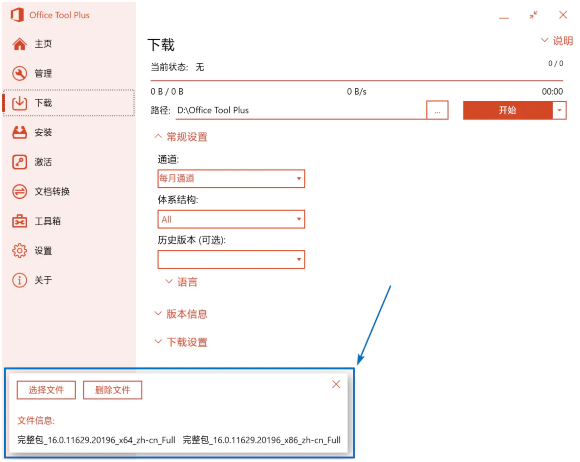
离线包已下载
安装
之后切换到「安装」选项卡,开始安装。安装过程跟在线安装基本一致。
在安装时,需要根据将要安装的 Office 的不同版本,对「Office 套件」项进行选择:
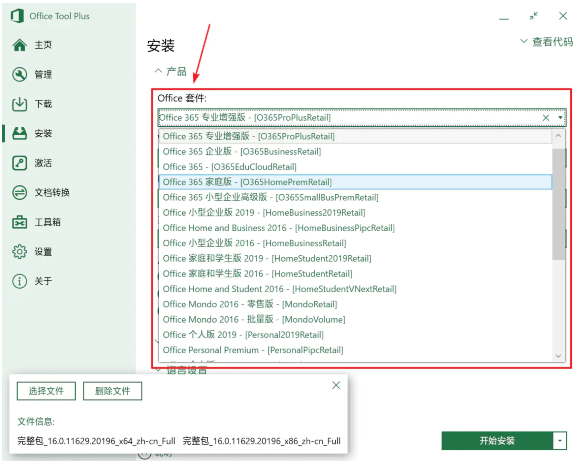
选择「Office 套件」
这里需要说明的是,由于 Visio 和 Project 是从 Office 中独立出来的,因此需要单独选择。
如下是一些常见的示例:
Office 版本 Office 套件 ID
| Office 2019 专业增强版(零售) | ProPlus2019Retail |
| Office 2019 专业增强版(批量) | ProPlus2019Volume |
| Office 2019 家庭和学生版 | HomeStudent2019Retail |
| Office 2016 专业增强版(零售) | ProPlusRetail |
| Office 2016 专业增强版(批量) | ProPlusVolume |
| Office 2016 家庭和学生版 | HomeStudentRetail |
| Office 365 个人版、家庭版 | O365HomePremRetail |
| Office 365 教育版、E3 等 | O365ProPlusRetail |
Visio 版本 Visio ID
| Visio 2019 专业版(零售) | VisioPro2019Retail |
| Visio 2019 专业版(批量) | VisioPro2019Volume |
| Visio 2016 专业版(零售) | VisioProRetail |
| Visio 2016 专业版(批量) | VisioProVolume |
| Visio 2019 标准版(零售) | VisioStd2019Retail |
| Visio 2019 标准版(批量) | VisioStd2019Volume |
| Visio 2016 标准版(零售) | VisioStdRetail |
| Visio 2016 标准版(批量) | VisioStdVolume |
Project 版本 Project ID
| Project 2019 专业版(零售) | ProjectPro2019Retail |
| Project 2019 专业版(批量) | ProjectPro2019Volume |
| Project 2016 专业版(零售) | ProjectProRetail |
| Project 2016 专业版(批量) | ProjectProVolume |
| Project 2019 标准版(零售) | ProjectStd2019Retail |
| Project 2019 标准版(批量) | ProjectStd2019Volume |
| Project 2016 标准版(零售) | ProjectStdRetail |
| Project 2016 标准版(批量) | ProjectStdVolume |
之后,根据自己的需要,在「应用程序」区选择将要安装的 Office 组件:
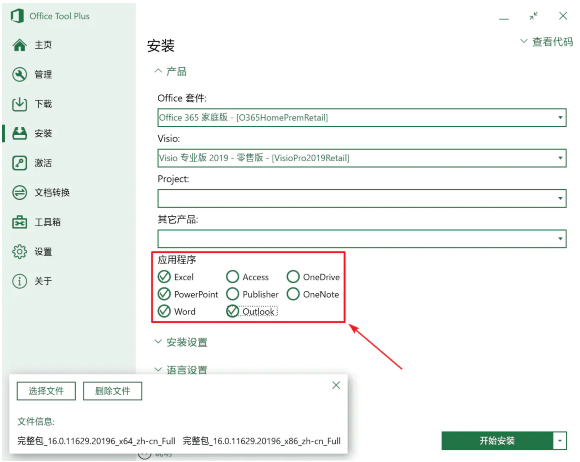
选择 Office 组件
「体系结构」部分,64 位(x64)Windows 可以安装 64 位和 32 位的 Office,32 位(x86)Windows 只能安装 32 位的 Office。至于如何选择,可以参考这篇文章。
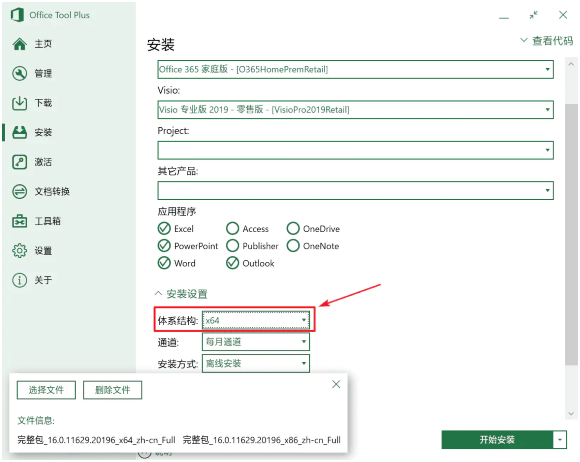
选择安装 64 位 Office
「通道」保持默认的「每月通道」即可。有需要的可以自行修改。
在全部选择完成后,点击「开始安装」,便会开始安装过程:
Office 离线安装
激活 Office
有条件请支持正版!正版 Office 不仅可以享受 Office 的全部权益,还能获得专业的售后支持服务。加上 Office 365 的价格一再降低,人们已经能够以较低的价格购买到正版的 Office。
可到微软中国商城购买 Office。可至 Office 产品比较页面查看 Office 各版本的区别,以决定购买哪种。
购买完成后,使用密钥激活 Office;或者将密钥绑定到微软账户,然后使用该微软账户登录 Office 即可。
暂时没有经济能力的,可以继续往下看。
为了使用 KMS 方式激活 Office,需要将先前安装的零售版 Office 转换为批量版,方法就是安装许可证书。根据已安装的版本,选择对应的批量版许可证书,然后点击「安装许可证」:
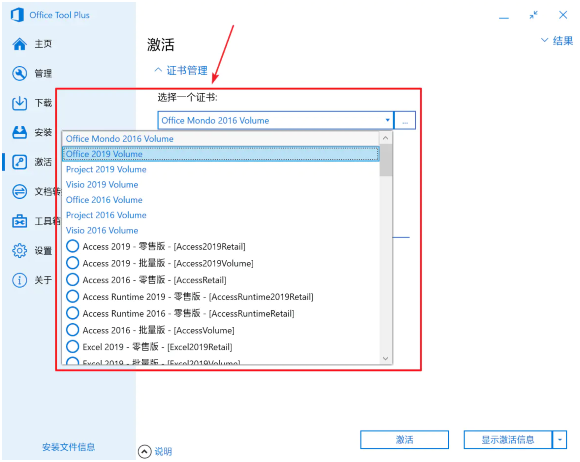
选择许可证
由于在安装许可证时会一并安装默认的 GVLK 密钥,因此这里不需要额外安装密钥。
之后,输入 KMS 服务器的地址,再点击「设定服务器地址」:
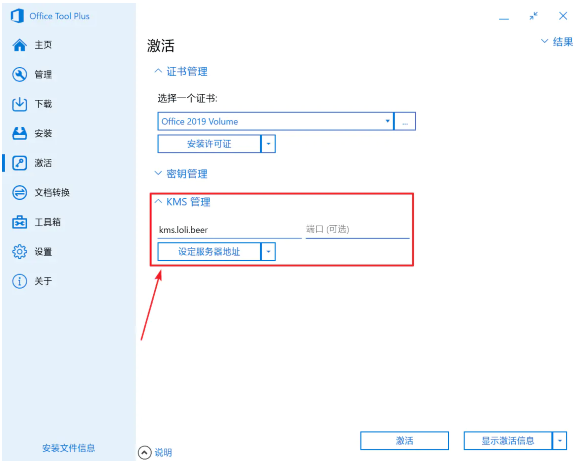
设定 KMS 服务器
最后,点击「激活」,等待激活完成。
以下是一些可用的 KMS 服务器:
kms.loli.beer
kms.loli.cab
kms.90zm.xyz
kms.cangshui.net
kms.03k.org
kms.myftp.org
zh.us.to
kms.chinancce.com
kms.digiboy.ir
kms.luody.info
kms.mrxn.net
kms8.MSGuides.com
xykz.f3322.org
kms.bige0.com
kms.shuax.com
kms9.MSGuides.com
kms.lotro.cc
www.ddddg.cn
cy2617.jios.org
enter.picp.net
关于激活 Office 的详细说明,请查看 OTP 内置的说明:
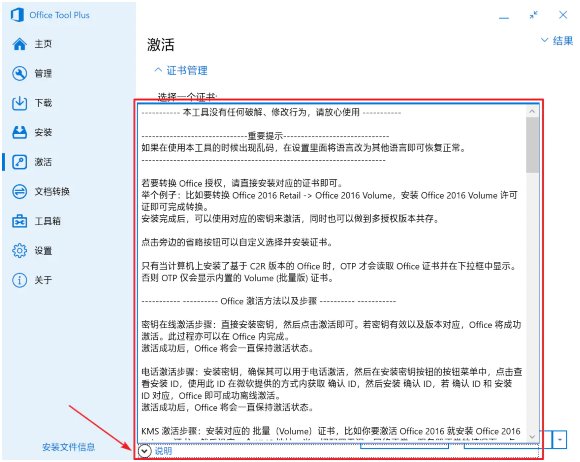
OTP 关于激活的说明
其它功能
目前的 OTP 还包含了一些其它的小功能,比如批量转换 Office 文档:
文档批量转换
以及工具箱,用于修复 Office 可能存在的一些异常问题:
OTP 工具箱
题外话
关于 OTP 的详细使用说明,其内部有许多地方都内置了说明:
OTP 内置的说明
并且在软件主界面还有经常更新的公告,讲解一些使用技巧。综上来看,OTP 实在是一款非常实用的小工具。
转自简书

 斯沃茨在2012年反对禁止网络盗版法案(SOPA)的抗议活动上发言
斯沃茨在2012年反对禁止网络盗版法案(SOPA)的抗议活动上发言
